
Origin : piece-me.org
File :
Source code :
List of supported functions :
Original description :
次はアプリケーションプログラムを作るつもりだったのですが、予定を変更して、もう一度計測プログラムをバージョンアップしました。
変更点は次のとおりです。
- 高速化しました。
- 機能をいくつか追加しました。詳細は、対応した機能の一覧をご参照ください。
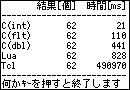
高速化した結果は、こうなりました。
| 結果[個] | 時間[ms] | |
|---|---|---|
| C(int) | 62 | 21 |
| C(flt) | 62 | 110 |
| C(dbl) | 62 | 441 |
| Lua | 62 | 828 |
| Tcl | 62 | 490970 |
約1.68倍の高速化です。
前回以降、P/ECE用Tclインタプリタを使って、簡単なボードゲームを作りかけていたのですが、実行速度が遅すぎて断念しました。
スクリプトを数行実行するたびに、数秒間止まるぐらい遅いです。
元々このP/ECE用Tclインタプリタは、コードサイズを小さくすることが目標で、速度は度外視だったのですが、それにしても限度があります。
そこで、少しは高速化することにしました。
とはいえ、Tclインタプリタ自体に手を入れると、複雑になったりコードサイズが増えて元の目標から外れるので、別の方法で高速化しました。
主にメモリ管理の高速化で、下記三点の変更を行いました。①②③の順に、高速化の効果が高かったです。
- ガーベージコレクタを高速RAMに転送して実行するようにしました。
ただし、常にカベージコレクタを高速RAMに配置すると無駄が大きいので、ガーベージコレクションの実行時のみ転送するようにしました。
P/ECEカーネルが、液晶データの変換やフラッシュメモリの書き換えルーチンを、一時的に高速RAMに転送して実行するのと同様の方法です。
P/ECEカーネルの仕組みで言うところの、’FRAM4領域’への転送です。 - ガーベージコレクタのスイープ処理を高速化しました。
これまでは、ガーベージコレクタがメモリブロックを開放するときに、P/ECE APIのpceHeapFree()を使用していました。
しかし、pceHeapFree()を呼び出すと、その都度、ヒープを先頭から走査しなおすことになり、速度低下の一因となっていました。
今回、ガーベージコレクタのメモリ開放処理を自前で実装して、スイープ処理を1パスで実行するようにしました。 - メモリ割り当てアルゴリズムを、ファーストフィット方式に置き換えました。
シンプルなメモリ割り当てアルゴリズムの中では、一番単純なファーストフィット方式が結局、最善と聞いた事があります。
ベストフィット方式とかにすると、処理が増えて遅くなるし、直感に反して却ってメモリ使用効率も悪くなるのだそうです。
P/ECE APIのpceHeapAlloc()は、ベストフィット方式のメモリ割り当てアルゴリズムが使用されていて、効率が悪い可能性があります。
そこで、pceHeapAlloc()のカーネルサービスベクタをフックして、ファーストフィット方式のメモリ割り当て処理に置き換えました。